Database design process
Database design process is a series of instructions detailing the creation of tables, attributes, domains, views, indexes, security constraints, and storage and performance guidelines. In this process, you implement all these design specifications.

The process starts with conceptual design and moves to the logical and physical design stages. At each stage, more details about the data model design are determined and documented. You could think of the conceptual design as the overall data as seen by the end-user, the logical design as the data as seen by the DBMS, and the physical design as the data as seen by the operating system’s storage management devices.
1. Conceptual design
Conceptual design is the process that designs a conceptual data model that describes the main data entities, attributes, relationships, and constraints of a given problem domain represents real-world objects in the most realistic way possible. It must embody a clear understanding of the business and its functional areas. The design must be software- and hardware-independent.
The process should follow a minimal data rule: All that needed is there, and all that is there is needed.
However, as you apply the minimal data rule, avoid excessive short-term bias. Focus not only on the immediate data needs of the business but on future data needs. Thus, the database design must leave room for future modifications and additions, ensuring that the business’s investment in information resources will endure.
The conceptual design has four steps:
1.1 Data analysis and requirements
In order to design appropriate data element characteristics that can be transformed into appropriate information, the efforts should focus on
- Information needs. What kind of information is needed? That is, what output (reports and queries) must be generated by the system, what information does the current system generate, and to what extent is that information adequate?
- Information users. Who will use the information? How is the information to be used? What are the various end-user data views?
- Information sources. Where is the information to be found? How is the information to be extracted once it is found?
- Information constitution. What data elements are needed to produce the information? What are the data attributes? What relationships exist among the data? What is the data volume? How frequently are the data used? What data transformations will be used to generate the required information?
The answers to those questions are from a variety of sources to compile the necessary information:
- Developing and gathering end-user data views.
- Directly observing the current system.
- Interfacing with the systems design group.
- Understanding of the total business.
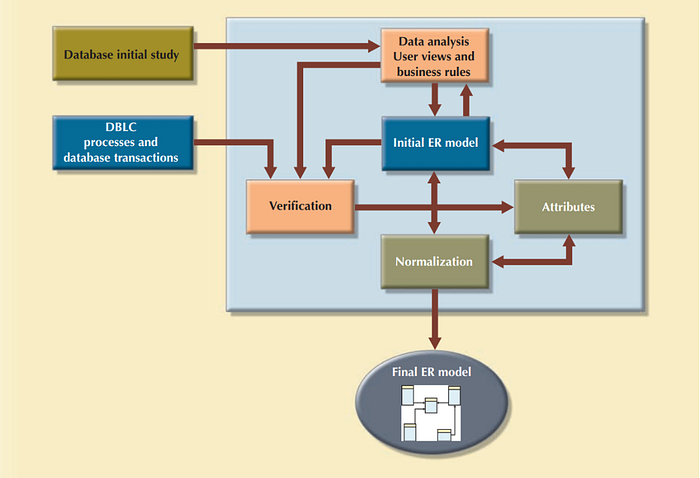
1.2 Entity relationship modeling and normalization
In this step, we could communicate and enforce appropriate standards to be used in the documentation of the design(diagrams and symbols, documentation writing style, layout, and any other conventions). Designers often overlook this very important requirement, especially when they are working as members of a design team.
After that, the designer could incorporate business rules into the conceptual model using ER diagrams by following the steps:
- Identify, analyze, and refine the business rules.
- Identify the main entities, using the results of Step 1.
- Define the relations among the entities, using the result of Steps 1 and 2.
- Define the attributes, primary keys, and foreign keys for each of the entities.
- Normalize the entities.
- Complete the initial ER digaram.
- Validate the ER model against the end users’ information and processing requirements.
- Modify the ER model, using the result of Step 7.
The activities often take place in parallel, and the process is iterative until you are satisfied that the ER model accurately represents a database design that can meet the required system demands
Below is the array of design tools and information sources that the designer can use to produce the conceptual model
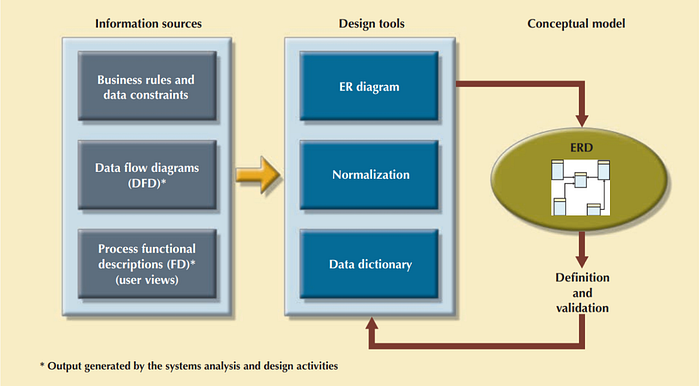
All objects (entities, attributes, relations, views, and so on) are defined in a data dictionary, which is used in tandem with the normalization process to help eliminate data anomalies and redundancy problems. During this ER modeling process, the designer must:
- Define entities, attributes, primary keys, and foreign keys. (The foreign keys serve as the basis for the relationships among the entities.)
- Make decisions about adding new primary key attributes to satisfy end-user and processing requirements.
- Make decisions about the treatment of composite and multivalued attributes.
- Make decisions about adding derived attributes to satisfy processing requirements.
- Make decisions about the placement of foreign keys in 1:1 relationships.
- Avoid unnecessary ternary relationships.
- Draw the corresponding ER diagram.
- Normalize the entities.
- Include all data element definitions in the data dictionary.
- Make decisions about standard naming conventions.
The naming conventions requirement is important, yet it is frequently ignored at the designer’s risk. Real database design is generally accomplished by teams. Therefore, it is important to ensure that team members work in an environment in which naming standards are defined and enforced. Proper documentation is crucial to the successful completion of the design, and adherence to the naming conventions serves database designers well. In fact, a common refrain from users seems to be: “I didn’t know why you made such a fuss over naming conventions, but now that I’m doing this stuff for real, I’ve become a true believer.”
1.3 Data model verification
It is one of the last steps in the conceptual design stage, and it is one of the most critical. In this step, the ER model must be verified against the proposed system processes to corroborate that they can be supported by the database model. Verification requires that the model be run through a series of tests against:
- End-user data views.
- All required transactions: SELECT, INSERT, UPDATE, and DELETE operations.
- Access rights and security.
- Business-imposed data requirements and constraints.
Because real-world database design is generally done by teams, the database design is probably divided into major components known as modules. A module is an information system component that handles a specific business function, such as inventory, orders, or payroll. Under these conditions, each module is supported by an ER segment that is a subset or fragment of an enterprise ER model. Working with modules accomplishes several important ends:
- The modules (and even the segments within them) can be delegated to design groups within teams, greatly speeding up the development work.
- The modules simplify the design work.
- The modules can be prototyped quickly.
- Even if the entire system cannot be brought online quickly, the implementation of one or more modules will demonstrate that progress is being made and that at least part of the system is ready to begin serving the end users.
As useful as modules are, they represent a loose collection of ER model fragments that could wreak havoc in the database if left unchecked. For example, the ER model fragments:
- Might present overlapping, duplicated, or conflicting views of the same data.
- Might not be able to support all processes in the system’s modules.
To avoid these problems, it is better if the modules’ ER fragments are merged into a single enterprise ER model. This process starts by selecting a central ER model segment and iteratively adding more ER model segments one at a time. At each stage, for each new entity added to the model, you need to validate that the new entity does not overlap or conflict with a previously identified entity in the enterprise ER model.
Merging the ER model segments into an enterprise ER model triggers a careful reevaluation of the entities, followed by a detailed examination of the attributes that describe those entities. This process serves several important purposes:
- The emergence of the attribute details might lead to a revision of the entities themselves.
- The focus on attribute details can provide clues about the nature of relationships as they are defined by the primary and foreign keys.
- To satisfy processing and end-user requirements, it might be useful to create a new primary key to replace an existing primary key.
- Unless the entity details (the attributes and their characteristics) are precisely defined, it is difficult to evaluate the extent of the design’s normalization.
- A careful review of the rough database design blueprint is likely to lead to revisions.
After finishing the merging process, the resulting enterprise ER model is verified against each of the module’s processes
- Identify the ER model’s center entity.
- Identify each model and its components.
- Identify each module’s transaction requirements
Internal: updates/inserts/delets/queries/reports
External: modeul interfaces - Verify all process against system requirments.
- Make all necessary changes suggested in Step 4.
- Repeat Steps 2–5 for all modules.
Keep in mind that this process requires the continuous verification of business transactions as well as system and user requirements. The verification sequence must be repeated for each of the system’s modules.
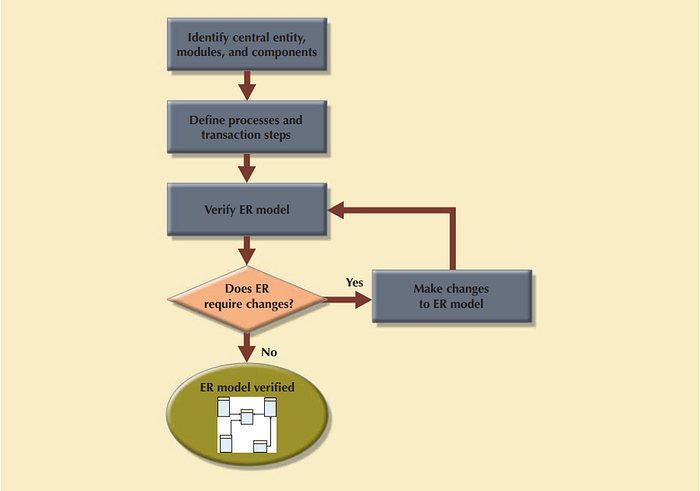
The verification process starts with selecting the central (most important) entity, which is the focus for most of the system’s operations.
To identify the central entity, the designer selects the entity involved in the greatest number of the model’s relationships. In the ER diagram, it is the entity with more lines connected to it than any other.
The next step is to identify the module or subsystem to which the central entity belongs and to define that module’s boundaries and scope. The entity belongs to the module that uses it most frequently. Once each module is identified, the central entity is placed within the module’s framework to let you focus on the module’s details.
Within the central entity/module framework, you must
- Ensure the module’s cohesivity.
- Analyze each module’s relationships with other modules to address module coupling.
Processes may be classified according to their
- Frequency (daily, weekly, monthly, yearly, or exceptions).
- Operational type (INSERT or ADD, UPDATE or CHANGE, DELETE, queries and reports, batches, maintenance, and backups).
All identified processes must be verified against the ER model. If necessary, appropriate changes are implemented. The process verification is repeated for all of the model’s modules. You can expect that additional entities and attributes will be incorporated into the conceptual model during its validation.
At this point, a conceptual model has been defined as hardware- and software-independent. Such independence ensures the system’s portability across platforms. Portability can extend the database’s life by making it possible to migrate to another DBMS and hardware platform.
1.4 Distributed database design
Although not a requirement for most databases, some may need to be distributed among multiple geographical locations. Processes that access the database may also vary from one location to another. For example, a retail process and a warehouse storage process are likely to be found in different physical locations. If the database data and processes will be distributed across the system, portions of a database, known as database fragments, may reside in several physical locations. A database fragment is a subset of a database that is stored at a given location. The database fragment may be a subset of rows or columns from one or multiple tables.
Distributed database design defines the optimum allocation strategy for database fragments to ensure database integrity, security, and performance. The allocation strategy determines how to partition the database and where to store each fragment.
2. DMBS software selection
DBMS software selection is critical, we should carefully study the advantages and disadvantages.
The common factors that affect the selection are:
- Cost.
- DBMS features and tools.
- Underlying model.
- Portability.
- DBMS hardware requirements.
3. Logical design
Logical design goal is to design an enterprise-wide database that is based on a specific data model but independent of physical-level details. It requires that all objects in the conceptual model be mapped to the specific constructs used by the selected database model.
The logical design generally performed in four steps:
- Map the conceptual model to logical model components.
- Validate the logical model using normalization.
- Validate the logical model integrity constraints.
- Validate the logical model against user requirements.
4. Physical design
Physical design is the process of determining the data storage organization and data access characteristics of the database to ensure its integrity, security, and performance. The storage characteristics are a function of the types of devices supported by the hardware, the type of data access methods supported by the system, and the DMBS.
The physical design consists of 3 steps:
- Define data storage organization.
- Define integrity and security measures.
- Determine performance measurements.
